AI inference is moving toward the edge because centralized cloud processing introduces latency, egress costs and data residency constraints that compound as inference volume scales. The decision of where to run inference is determined by five workload characteristics: latency tolerance, data volume, compliance requirements, operational resilience needs and cost profile over time. Most production architectures resolve this by splitting responsibilities between cloud and edge, with the operational overhead of managing a distributed inference fleet remaining the primary factor that determines when the transition is viable.
For most of the past decade, the default architecture for AI in enterprise products was straightforward: train models centrally in the cloud, run inference in the cloud, send results back to users or systems via API. That model worked well when AI was used sporadically and when latency of a second or two was acceptable. Neither of those conditions holds in 2026.
Inference workloads now account for roughly two-thirds of all AI compute, up from one-third in 2023. The shift from experimentation to production deployment has placed inference at the center of infrastructure strategy. And as inference scales, the economics and performance constraints of running it entirely in the cloud have become increasingly difficult to ignore.
The response, across industries and product types, has been a structural move toward running inference closer to where data is generated. This is the core premise of edge AI inference: rather than sending data to a remote server and waiting for a result, the model runs locally, on the device, gateway, or on-premises node where the data originates.
This article covers what that shift means in practice, which workloads are genuinely suited to edge inference, what the hardware and model landscape looks like right now, and what product teams need to account for architecturally before making the move. For teams who are still deciding whether edge computing belongs in their stack at all, the earlier articles in this series cover the foundational concepts of edge computing and how to decide which workloads belong at the edge versus in the cloud.
What edge inference actually means
AI inference is the process of applying a trained model to new data in order to produce a result: a classification, a prediction, a generated output, an anomaly score. Training, the computationally intensive process of building a model in the first place, requires centralized infrastructure with substantial GPU capacity. Inference is a different matter entirely.
Running inference in the cloud introduces three recurring costs: latency from the round-trip to a remote server, data transmission costs from sending raw data upstream, and privacy exposure from moving sensitive data across public networks. For applications that run inference infrequently or without time sensitivity, those costs are manageable. For applications that run inference continuously, at high volume or in latency-critical contexts, they compound quickly.
Edge inference addresses all three directly. The model runs locally, results are produced in milliseconds rather than hundreds of milliseconds, raw data stays within the local environment, and only processed outputs or anomalies travel to central systems. In safety-critical applications such as autonomous vehicles or industrial robotics, sub-50 millisecond response times are required, which rules out a cloud round-trip by design.
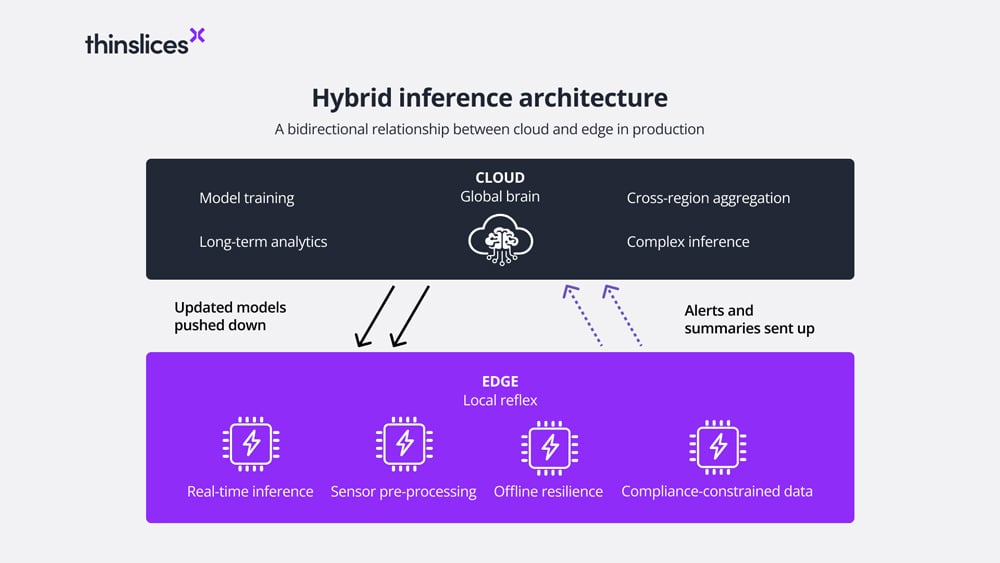
The distinction matters architecturally because it changes what the cloud is for. In an edge inference model, the cloud handles training, model updates and long-term analytics. The edge handles prediction. The two layers remain interdependent, but the inference workload shifts away from centralized infrastructure.
Why 2026 is a meaningful inflection point
The practical case for edge inference has existed for years. What has changed in the past 18 months is the hardware and software infrastructure required to act on it. Three developments have converged to make edge inference genuinely viable at production scale.
Model compression has matured
Model size is no longer the barrier it was. Most enterprise inference tasks, including classification, summarization, anomaly detection and domain-specific question answering, do not require frontier-scale models. Over 40% of enterprise AI workloads are expected to migrate to smaller, more efficient models by 2027, because the majority of real-world tasks simply do not need the scale of the largest general-purpose models to produce accurate results.
What has made this shift possible is a set of compression techniques, primarily quantization, pruning and knowledge distillation, that reduce model size significantly without proportional loss in accuracy. The practical result: capable AI models now run on standard edge hardware. A compact language model with 4-bit quantization fits in under 700MB of RAM and runs comfortably on a modern smartphone. Larger compressed models run on purpose-built edge servers at speeds fast enough for real-time applications. For product teams, this means that deploying AI inference locally is an engineering decision, not a hardware procurement problem.
Purpose-built hardware is widely available
Specialized neural processing units (NPUs) are becoming standard in edge devices, delivering AI tasks while consuming minimal power. Cutting-edge models now achieve up to 26 tera-operations per second at only 2.5 watts, making them at least six times more efficient than CPUs and mainstream GPUs for neural network tasks.
NVIDIA's Jetson Orin series, Qualcomm's Snapdragon X Elite, and AMD's Ryzen AI Max processors have each established production-grade edge inference as a realistic deployment target. During the first quarter of 2026, Cisco, Dell, HPE and NVIDIA also launched updates for AI inference in radio access networks, including partnerships with telcos to push more processing power into edge networks. The infrastructure investment across the industry is not experimental. It reflects a broad recognition that centralized data centers cannot accommodate the inference demands of distributed AI at scale.
Open-source deployment tooling has caught up
Two years ago, deploying a language model on edge hardware required significant engineering effort. That barrier has largely gone. The open-source ecosystem around edge AI inference has matured to the point where a model can go from selection to local deployment in under an hour on standard hardware, without specialist infrastructure knowledge.
The frameworks that make this possible, including llama.cpp, ExecuTorch and ONNX Runtime, cover everything from CPU-based inference on ARM devices to production-ready deployment on mobile and embedded systems. Tools such as Ollama have made local model serving accessible to engineering teams who are not machine learning specialists. The engineering overhead that previously made edge AI inference impractical for product teams has dropped substantially, and it continues to fall.
The cost case for edge inference
The financial argument for edge inference is not straightforward in every context, but for data-intensive applications it is increasingly difficult to ignore.
In 2026, the average cost per inference in the cloud is roughly $0.0005 to $0.001. Multiplied by millions of requests, which is common in retail analytics or smart city traffic monitoring, the operating cost climbs considerably. Data egress fees for high-bandwidth video streams can add an additional $0.02 per gigabyte, pushing total costs higher than edge solutions that keep data local. A comprehensive total cost of ownership analysis shows that for high-volume, low-latency workloads, edge AI can be 30 to 50% cheaper over a five-year horizon.
The crossover point depends on utilization. On-device inference amortizes hardware cost over the device lifetime. Cloud GPU charges per second of compute. At high utilization above 70% of hours, cloud GPU remains cost-competitive. At low or moderate utilization, on-device wins because there is no cost for idle capacity.
For early-stage products and validation phases, cloud inference remains the right starting point. The pay-as-you-go model lowers the barrier to entry, avoids upfront hardware expenditure and allows teams to validate demand before committing to distributed infrastructure. The case for edge inference becomes financially clear when three conditions are met: request volume is high enough that per-inference cloud costs are material, data volume is large enough that egress fees compound meaningfully, and the deployment will run long enough for the hardware investment to amortize. Those conditions describe a significant number of production AI deployments.
The five workload characteristics that determine inference placement
Not every AI workload belongs at the edge. The decision follows the same five-dimensional framework that applies to workload placement generally, applied specifically to inference.
Latency tolerance
This is the most direct filter. If a delay of 100 to 200 milliseconds between data generation and an AI-driven decision would affect safety, financial outcome, or user experience, the inference workload belongs at the edge. Real-time fraud detection on transaction streams, autonomous vehicle control systems, industrial vision systems that detect manufacturing defects, and voice AI pipelines are all examples where cloud round-trips introduce unacceptable delay.
If the application can tolerate latency of a second or more, as is the case with most analytics dashboards, batch processing jobs and non-real-time recommendation systems, cloud inference is the simpler path.
Data volume and type
Vision workloads are the clearest case for edge inference. A single high-definition video stream generates several terabytes of bandwidth per month. Edge devices reduce this burden by processing data locally and sending only the results, such as tags, alerts, or cropped images, to the cloud. This cuts upstream bandwidth consumption by up to 80%. The same logic applies to high-frequency sensor data in industrial environments: a factory with thousands of sensors does not need to transmit every raw reading upstream. It needs to transmit alerts when readings fall outside expected ranges, which is precisely what local inference produces.
For text-based workloads without significant data volume, the bandwidth argument is less compelling, and cloud inference may remain the right choice regardless of other factors.
Compliance and data residency
Regulated industries present the clearest-cut cases for edge AI inference. In healthcare, HIPAA requires strict controls on the movement of patient data. A 50-physician primary care network deploying a medical-variant language model on local edge servers for HIPAA compliance ensures that sensitive data never leaves the facility, while still delivering sub-second diagnostic support to clinical staff. In financial services, DORA imposes explicit requirements on where data is processed: a payments platform running real-time transaction scoring on edge nodes within each jurisdiction ensures that raw transaction records never cross a border, simplifying compliance considerably compared to building cross-region data governance frameworks around centralized cloud processing. In any context where raw inference inputs include personal, financial, or biometric data subject to residency requirements, local processing eliminates a category of compliance risk that cloud inference cannot.
The EU AI Act, which came into force in 2025, adds a further dimension. High-risk AI systems require rigorous audit trails. Edge inference simplifies those audits by limiting data movement and concentrating processing within defined organizational boundaries.
Operational resilience
Cloud-dependent inference creates a single point of failure: network connectivity. For applications running in environments with intermittent or unreliable connectivity, including industrial sites, logistics operations, remote healthcare facilities and agricultural settings, inference that depends on a cloud connection will fail at exactly the wrong moment. Edge inference continues to produce results regardless of upstream connectivity, which is an architectural property rather than a nice-to-have. For a deeper treatment of resilience as an architectural consideration, read our article on Edge computing vs. cloud computing: how to choose your architecture.
Model complexity requirements
Not all inference tasks require the same model scale. For most classification and domain-specific tasks, 3 to 7 billion parameter models with 4-bit quantization deliver performance comparable to much larger models at a fraction of the computational cost. Tasks that genuinely require frontier-scale reasoning, complex multi-step generation or broad general knowledge are better served by cloud inference. Tasks that require specialized, domain-specific outputs, such as industrial fault classification, medical triage scoring, or financial transaction categorization, can be addressed effectively by smaller fine-tuned models running at the edge.
The hybrid pattern that most mature architectures use
The most common production pattern is not a choice between cloud inference and edge inference. It is a deliberate split based on workload characteristics.
The cloud handles training on aggregated historical data, model improvement and updates, complex inference for non-time-critical tasks and long-term analytics. The edge handles real-time inference, high-volume sensor or video processing, compliance-constrained data and functions that must continue during network outages. Updated models push down from cloud to edge as they improve. Alerts, anomalies and summarized insights flow from edge to cloud for broader analysis.
A practical example of this pattern in manufacturing: a YOLO v11 computer vision model analyzes camera frames at 30 frames per second to detect visual defects. When a defect is detected, a Phi-4-mini language model generates a structured defect report in natural language. Total pipeline latency is 120 milliseconds on an NVIDIA Jetson Orin NX, fast enough for real-time quality control on high-speed production lines. The entire system runs air-gapped, with no cloud dependency during operation.
A common routing pattern in text-based applications works similarly: a classifier routes high-volume, domain-specific requests to a smaller local model handling the majority of traffic, while complex or out-of-domain queries route to a cloud-hosted frontier model. An e-commerce retailer handling 200,000 monthly conversations, for example, can route 95% of interactions to a local small language model and 5% to a large cloud model, achieving a significant reduction in total inference cost without sacrificing response quality for edge cases.
What product teams need to account for before moving inference to the edge
The architectural case for edge inference can be clear before the operational implications are fully understood. Three areas require deliberate planning.

Model management across a distributed fleet
A model running in the cloud is updated in one place. A model running on edge hardware requires a coordinated update process across potentially thousands of devices. This includes versioning, rollback capability, health monitoring and security patch management. Without automated orchestration tooling, maintaining consistency across a distributed model fleet introduces significant operational overhead. Teams planning edge inference deployments need to design the model lifecycle management pipeline before the first device ships.
Security at the device level
Moving inference to the edge distributes the security perimeter. Each edge device running a model represents an attack surface. Device-level authentication, encrypted model storage, secure boot processes and zero-trust network architecture are standard requirements for production edge AI deployments. These are solvable problems, but they require upfront engineering investment that cloud-only teams do not typically have in place.
Hardware procurement and lifecycle management
Cloud inference scales with a configuration change. Edge inference scales with hardware. Procurement cycles, physical installation, on-site maintenance, power and cooling requirements and end-of-life planning are all operational responsibilities that cloud deployments do not carry. For teams without prior experience managing distributed hardware infrastructure, the gap between the architectural decision and the operational reality can be significant. The right time to introduce edge inference is when the business case is clear enough to justify building or acquiring that operational capability.
Where edge AI inference is heading
By late 2026, the real competitive battleground in AI is shifting to edge inference. Organizations are recognizing that their most valuable data is generated at factories, retail locations, and remote operational sites where real-time decisions are critical.
Two developments beyond the immediate term are worth tracking. The first is the continued maturation of agentic AI systems, which are capable of autonomous decision-making and multi-step task execution. These systems require inference at low latency across extended interaction sequences, making edge infrastructure an architectural necessity rather than an optimization. The second is the development of 5G and emerging 6G connectivity, which improves the network layer that edge deployments depend on and enables new use cases in mobile and vehicle-based environments.
For product teams, the near-term question is not whether AI inference will move toward the edge. The direction is clear. The question is which workloads in a specific product justify the investment now, and what operational foundations need to be in place before that investment produces reliable outcomes.
Conclusion
Running AI inference at the edge is not a replacement for cloud inference. It is a placement decision, and the criteria are specific: latency requirements, data volume, compliance constraints, resilience needs and cost profile at scale. For workloads that meet those criteria, edge AI inference is no longer an advanced capability. The models, hardware and deployment tooling are production-ready.
The sectors where this is most immediately consequential are also the most familiar to teams building regulated or data-intensive products. In financial services, real-time transaction scoring and fraud detection require inference speeds that cloud round-trips cannot reliably deliver. In healthcare, patient monitoring and diagnostic AI need both sub-second response times and guarantees that sensitive data does not leave the facility. In industrial and logistics environments, the cost of a connectivity-dependent system failing at a critical moment is not abstract.
For product teams, the practical next step is to audit current inference workloads against the five criteria covered in this article, identify the candidates where edge deployment would deliver measurable improvement, and assess whether the operational foundations are in place to support it. The architecture decisions made now will determine what becomes feasible at scale over the next two to three years.
Frequently asked questions
What is AI inference at the edge?
Edge inference is the process of running a trained AI model locally, on a device, gateway or on-premises node, rather than sending data to a cloud server for processing. The model executes where the data originates, producing results in milliseconds without a network round-trip.
Which AI models can run at the edge in 2026?
A wide range of models are viable for edge deployment, from compact vision models handling real-time image classification to small language models in the 3 to 10 billion parameter range handling text tasks. Model compression techniques including quantization and pruning have made it practical to run capable models on hardware including NVIDIA Jetson devices, Apple Silicon and modern NPU-equipped workstations.
When does it make financial sense to move inference to the edge?
Edge inference typically becomes cost-effective when request volume is high, data volumes make egress costs material, and the deployment will run long enough to amortize hardware investment. The crossover point varies by application, but for high-volume, data-intensive workloads the five-year TCO advantage of edge over cloud can reach 30 to 50%.
What are the main operational challenges of edge inference?
The three primary challenges are model lifecycle management across a distributed device fleet, security at the device level rather than at a centralized server, and hardware procurement and maintenance overhead. All are manageable with proper planning, but they require operational investment that cloud-only teams do not typically carry.
Can edge inference and cloud inference be used together?
Yes. Most mature architectures combine both. A common pattern runs real-time inference locally at the edge while using cloud infrastructure for model training, complex or low-frequency inference, and long-term analytics. Each layer handles what it does best, and the two reinforce each other over time as models trained centrally are deployed and improved at the edge.